Building High-Impact Growth Engineering Teams
Currently doing growth at Anthropic. I've spent years leading Growth Engineering organizations at MasterClass and Opendoor, advised dozens of companies and taught over 100 students in my Growth Eng course. My advising capacity is limited, but feel free to reach out.

Companies I've Helped







Articles and Talks




Past Growth Eng Students













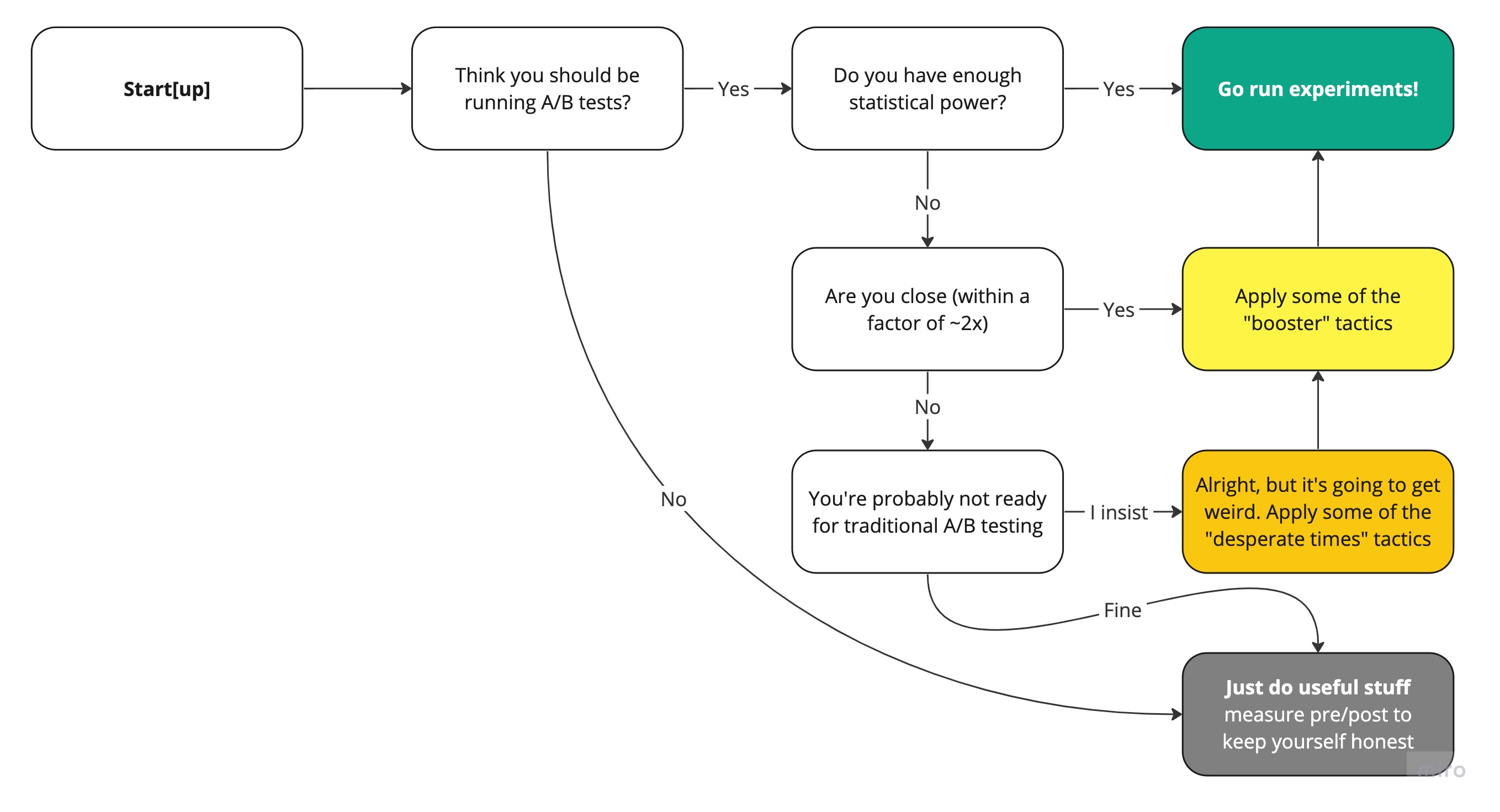
How I Can Help
MarTech Audit and Roadmap
Comprehensive assessment of your current martech and growth tech stack, processes, and team structure. Includes a detailed roadmap for improving your Growth Engineering capabilities and ongoing implementation support.
Get an Audit →Growth Engineering Advising
Hands-on mentorship for Growth EM and PMs ramping up to guide your team through growth challenges. Includes weekly strategy sessions, technical guidance, and executive alignment to ensure your growth initiatives succeed.
Book Advisory →Tailored Growth Workshops
Level up your Growth Engineers through a tailored version of the Growth Eng course that is focused on the industry, stage and maturity of your team. Customized to address your most pressing growth challenges and opportunities.
Schedule Training →