Over the past semester, I participated in an Independent Study in Behavioral Economics with Professor Jason Dana. Here's what we've been up to:
Mechanical Turk is Amazon's 'artificial artificial intelligence' service. Named after a fake chess-playing machine in the late 17th-18th century, According to Amazon, MTurk is a
Named after a fake chess-playing machine in the late 17th-18th century, According to Amazon, MTurk is a
marketplace for work that requires human intelligence. The Mechanical Turk web service enables companies to programmatically access this marketplace and a diverse, on-demand workforce. Developers can leverage this service to build human intelligence directly into their applications
It's a service that attempts to match people to small, bite-size units of work that are unsuitable for machines.
For example: You have a list of thousands websites and want to know which ones are appear to be well-designed. Algorithms to quantify taste do not yet (sadly) exist; instead, either look through the websites yourself, or offer the task to Mechanical Turk. Turkers, as the workers are called, are then paid 5 cents (or however much you offer) to rate each website. Hundreds of people can work on your classification task in parralel, saving time and money.
Common uses of Mechanical Turk include transcribing audio, identifying photos, or answering opinion surveys.
The Cheating Problem
Without oversight, what prevents Turkers from voting randomly? For objective tasks, you could manually go over each result yourself, but this would be exteremely time-intensive and defeat the purpose. For subjective tasks, even that wouldn't be possible - who knows if the Turker's choice of 3/10 for some website was his actual opinion or a random choice?
There are a couple of approaches that work here. You could try to get multiple Turkers to do each task and make sure they agree on the answers. You could do part of the work yourself, (set a gold standard) and verify Turker quality by how well they do on the tasks to which you now know the right answers. Finally, you can restrict your Turker employee base to a highly-qualified one, limiting your employee pool to those who have done good work before. As a side note, companies like CrowdFlower try to restrict and manage for high-quality workers on your behalf; if you're willing to pay more for your automated tasks, I've heard good things about them.
Amazon measures this 'done good work before' metric by looking at the Turker's HIT Approval Rate - the % of tasks that this worker has done in the past that were subsequently accepted by the employer. Limiting your workers to 95%+ is a standard way of trying to obtain only high-quality responses.
The Research Question
The question, then, is whether limiting the Turkers to those with a high acceptance rate is an effective way of making sure they don't cheat. We were also wondering where the cutoff for cheaters was and whether the amount of money offered for the task would affect the amount of cheating.
The Setup
Our experiment is as simple as possible:
The idea is based on an experiment Prof. Dana has run at Solomon Behavioral Labs at Penn as well as abroad [that we should probably link to/cite here]. We can't tell if any particular individual is cheating - perhaps they happened to flip heads - but in the aggregate, if we ask 50 homogenous Turkers to flip a coin and see how many heads we get, 50 heads indicates that the Turkers are a dishonest bunch, while 25 heads and 25 tails would indicate a fair and friendly group of turkers.
We offered the same task to 50 turkers in one of several groups, varying by HIT Approval Rate. An informal survey (IE, we asked one of Prof. Dana's grad students) suggested that cutoffs of <89%, 90-94%, 95-97%, 98-99% and 100% would be reasonable. We also offered the task to a group of Turk newbies (filtered by the fact that they had less than 20 tasks completed under their belt).
Offering 2c for tails and 4c for heads, we hoped to see how rampant cheating for subjective tasks was amongst various groups of accomplishment.
The Results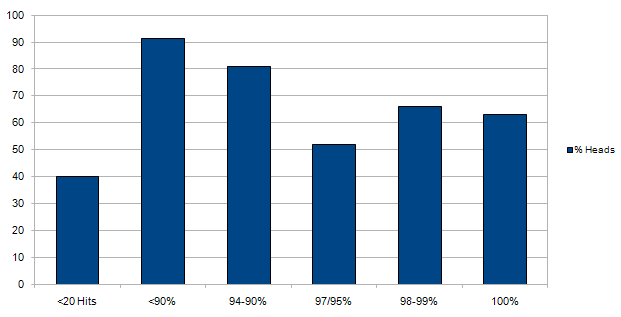 The data did not dissapoint. Excluding the 95-97% anomaly, the trend was clear: the better your Turkers, the more honest (by and large) they would be when offered subjective tasks where they could cheat without being detected.
The data did not dissapoint. Excluding the 95-97% anomaly, the trend was clear: the better your Turkers, the more honest (by and large) they would be when offered subjective tasks where they could cheat without being detected.
Since this was our first attempt at Mechanical Turk, though, we did not do as good of a job with the price offered or the marketing of the task (we named it 'Project Random'). As a result, we got only 158 participants (out of a possible 300), and only 19 100%-ers. Clearly, the price offered would have to go up.
How do you think offering more money affected the cheating chart? Should cheating go up or down, as a whole, if we offer 5c/10c instead of 2c/4c? Should any groups be more or less affected than average by an increased incentive to cheat?
Update: Part 2 is available here.
Tags: #behavioral-economics